阿里云轻量服务器 香港
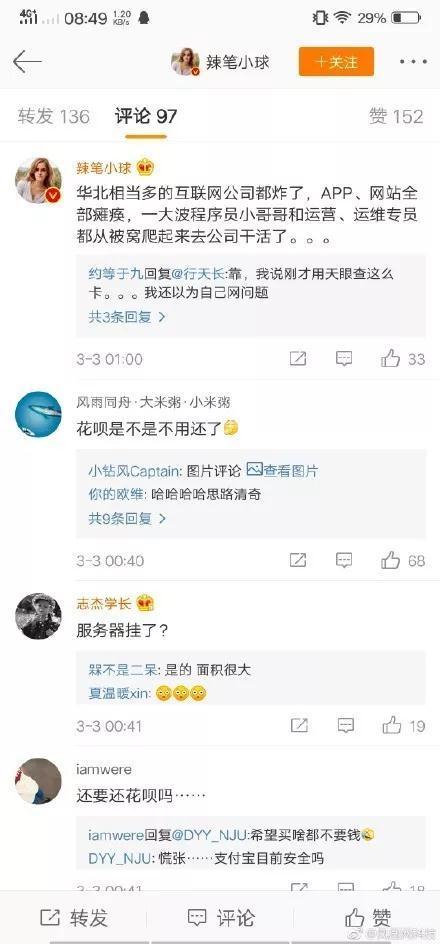
今日上午,阿里云多位用户在微博反映业务无法正常访问,“全线业务不能使用…”,“我们的十几台服务器全部在华北2上,瘫痪了一个小时,导致我们的App和网站一个小时无法访问…”
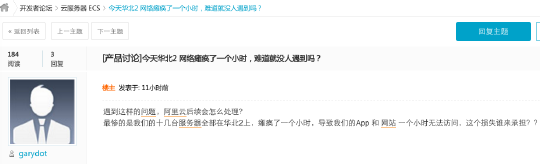
的确,云的问题最容易引发关注及讨论,因为云上承载了大量的用户业务,一旦发生故障也就直接导致云用户的在线业务无法开展,进而带来损失。

“2016年7月6日上午10点22分华北2地域可用区A由于网络设备出现异常,导致部分产品访问受到影响;经过紧急处理,网络抖动问题已于11点16分恢复。我们将尽快对此次故障进行复盘,降低同类故障发生概率。再次向您致以歉意。”阿里云在回应中称。
最近阿里云发生的较严重的故障是在1年前,2015年6月21日,阿里云香港节点9点30分左右突然全线小时。据阿里云回应称,故障因香港运营商IDC电力问题所致。
其实,伴随着云计算的发展,全球各地的云也发生了众多大大小小的故障,《黑客来了》就盘点了这些重要的故障事件:
2009年6月,一次罕见的事故让一些客户失去亚马逊EC2服务5小时,但是大多数客户都将其看做是成长之痛。这种有点奇怪的回应方式部没有持续,在一次分布式阻断式服务攻击和漫长的电子邮件管制之后,亚马逊的灾难响应协调和客户关系开始缺失。
2010年5月,一些列表面上看起来不相关的事故在亚马逊弗吉尼亚数据中心再次上演,在一周的跨度内导致了三次不同的宕机。第一次是不间断电源(UPS)转换到备份电源时失败,一机架的服务器挂了;第二次发生在四天之后,一个电源分配箱短路,导致服务中断8小时。最后两天后,一辆汽车撞击了电线杆子,切断了数据中心的电源,导致半小时宕机。不管有关系没关系,是不是大事件,这么短的时间发生这三次宕机对于任何厂商来说都不可能是个小事。
2009年6月,Rackspace遭受了严重的云服务中断故障。供电设备跳闸,备份发电机失效,不少机架上服务器停机。这场事故造成了严重的后果。
2011年4月22日,亚马逊云数据中心服务器大面积宕机,这一事件被认为是亚马逊史上最为严重的云计算安全事件。当时,信息寻找可用的设备把自己作为备份嵌入到这些设备中时,一个错误路线的通讯移动把一连串的亚马逊EBS(弹性块存储)通讯量发送到一个重新镜像的风暴。这是一种反常的现象。这引起了一系列事件,最终导致亚马逊在美国东部地区的许多服务中断。这个故障持续了大约四天时间。
2011年8月,亚马逊位于都柏林的数据中心遭遇雷击,造成大规模停电,导致亚马逊的EC2云计算平台停止运转。此次事故是由于数据中心附近的一个变压器被雷电击中,引起爆炸和火灾阿里云轻量服务器 香港,连带附近的供电设施无法启动导致停电,发电器无法启动,致使整个系统停电。
2012年2月28日,由于“闰年bug”导致微软Azure在全球范围内大面积服务中断,中断时间超过24小时。
2012年6月14日,Amazon位于美国东部的数据中心出现故障,并影响了AWS多项云服务以及基于之上的Heroku、Quora等知名网站。事故是由公共电网故障引起,并引发了一系列连锁故障。
2012年7月26日,Azure故障,导致西欧用户受影响。微软对故障的解释是“由于错误配置了网络设备导致了西欧区域的服务网络中断”。此次中断持续2.5小时。
2014年8月18日,Azure云在一次作为每月补丁日发布的Windows 8.01安全补丁之后导致部分用户中断服务长达5个小时,引发技术问题。微软报告称,Azure服务例如虚拟机网站、自动化、备份和站点恢复都在多个地区出现中断。
2014年11月,Azure发生的将近11个小时的故障。多个主要Region的存储服务出现问题,大量客户在此之间受到影响。影响了19种Azure服务,涉及12个Region,当时似乎只有澳大利亚数据中心幸免于难。
2014年11月2日中午12点,腾讯云在上海、广州两地的服务器出现故障,导致使用该服务器的用户出现无法正常登录、连接不稳定等现象。故障持续约两小时。
2015年6月6日,青云的服务商睿江科技机房因雷暴天气引发电力故障,导致青云广东1区全部硬件设备意外关机重启,青云官网及控制台短时无法访问、部署于GD1的用户业务暂时不可用。
2015年3月16日,微软有两项Azure公有云服务中断了2个多小时,美国中部客户受到影响,微软称这次故障是“网络基础设施的问题”。这次故障从美国中部时间下午1点开始,影响到微软Azure虚拟机(基础设施即服务)和Azure云服务(平台即服务)产品的客户,微软在其Azure状态网页上面报告了这次故障。返回搜狐,查看更多